LitSumm
Literature summaries for ncRNA
What does the literature say about that ncRNA you’re starting to study? What papers might be intersting to read bout its function, structure or disease relevance?
- What is it? LitSumm is an early (mid-2023) agent-like pipeline designed to write automated, cited literature summaries for non-coding RNAs (ncRNAs) on RNAcentral.
- The Pipeline: We pull sentences from EuropePMC, cluster them (SentenceTransformers + UMAP + HDBSCAN) to fit the then-tiny 4k token limit, prompt GPT-4-turbo for a summary, and run a battery of automated reference/veracity checks to keep it honest.
- The Output: We generated 4,618 cited summaries (94% rated good/excellent by expert raters) for about $0.05 and 29 seconds per run.
- What I’d change now: Topic modeling was necessary due to context constraints but is actually a bit shit because it blended unrelated contexts. If I built it today, I’d use RAG, or full agent with EuropePMC search tools.
For proteins, you can often get a handle on these questions from the UniProt page, especially for curated ones, because curators and some automated algorithms have created summaries of these aspects of the protein. However, this kind of thing didn’t really exist for ncRNA.
This was why I built LitSumm!
LitSumm was designed to produce literature summaries (hence the name) for ncRNA, where there is a lack of available people to produce these summaries. That meant it had to work without a human in the loop, and produce high-quality, cited and accurate summaries with no intervention.
You can read the paper about LitSumm at DATABASE: https://doi.org/10.1093/database/baaf006
What’s below is a less formal, maybe sometimes more detailed description of the work, and some of the stuff that didn’t work along the way.
Existing Architecture
LitSumm was built on an existing piece of code - LitScan - that exists at RNAcentral to connect ncRNAs to the literature aout them. LitScan uses the EuropePMC API to search for papers mentioning the RNA, and then checks that uisng a regex on the fulltext to find the mentions of the RNA. LitScan then extracts every sentence from the literature that mentions the RNA, and puts them in the RNAcentral database. You can see them on some RNA pages, where a sentence from every paper is displayed.
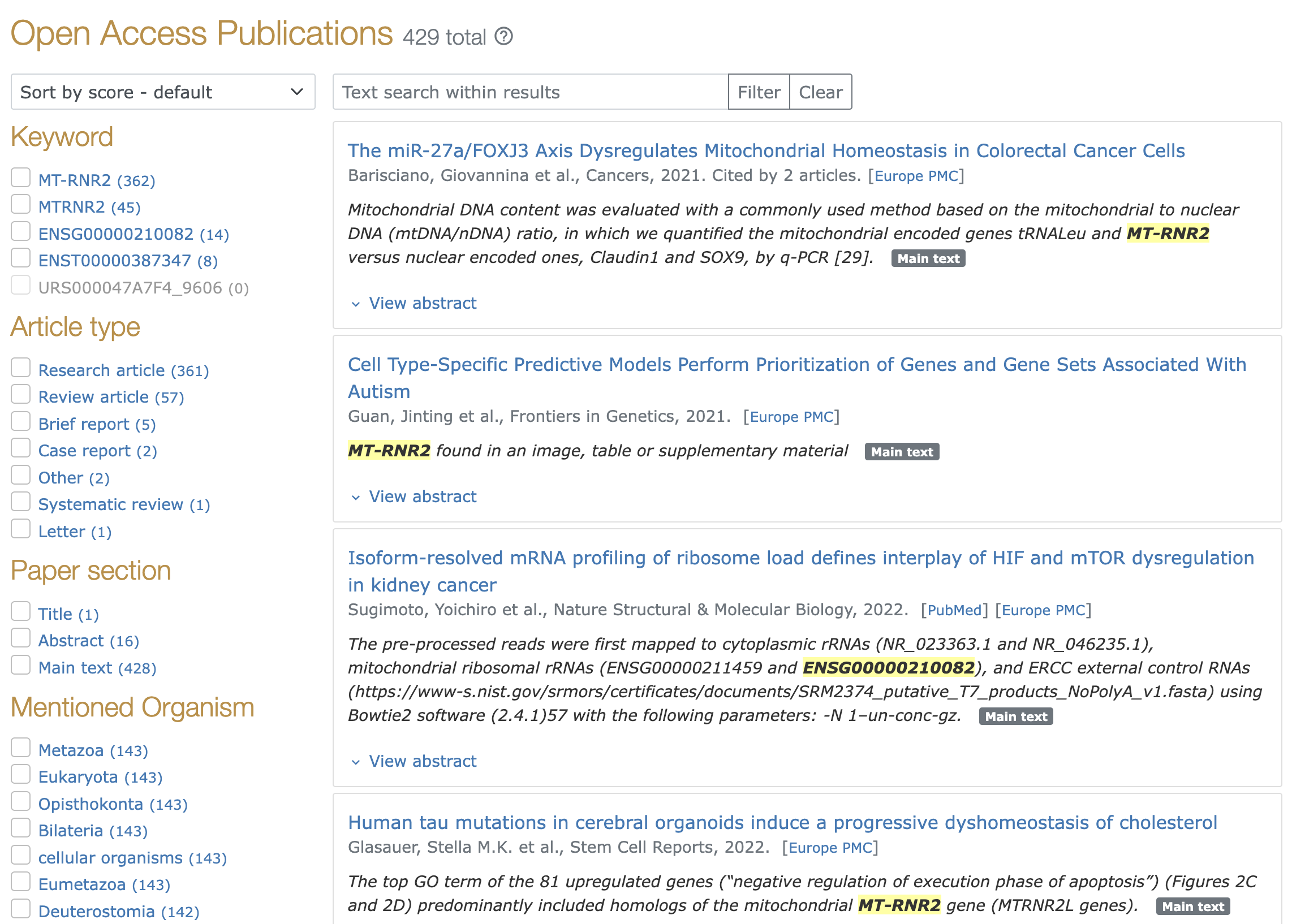
While this linkage works and you can search within mentioning sentences to get to potentially useful papers, it doesn’t give you much of an overview. That’s where LitSumm somes in.
The LitSumm architecture
Being generous, LitSumm was an agent before agents were cool:
- Driven by an LLM making decisions about what to do
- Sort of using tools (though not defined as such)
- Self-reflection and checking
LitSumm also has a strong focus on information provenance and minimization of hallucination. I think it was one of the most reliable systems at the time it was published.
This is the flow diagram for LitSumm, which I first came up with in mid-2023, and was essentially unchanged for the version that went into production.
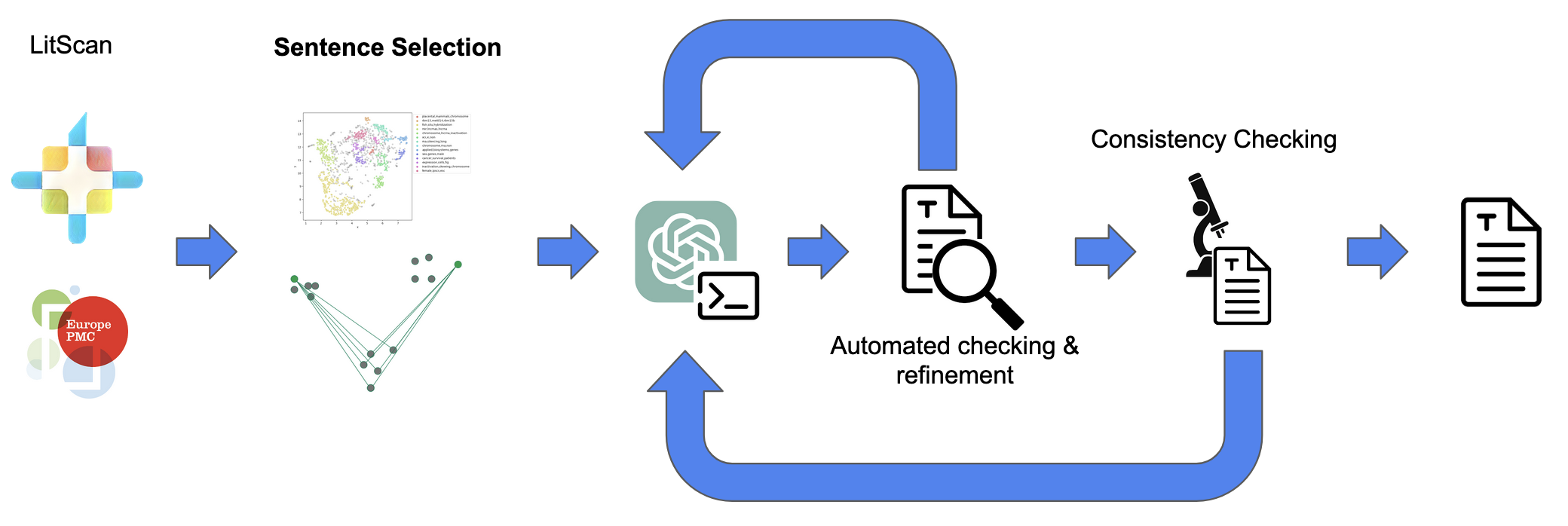
The system works in four stages, broadly. At the time, it was necessary to heavily restrict the amount of text in the LLM context, so the millions of sentences we had needed to be condensed down a lot before we could do anything with them. This was the sentence selection process.
Sentence selection
The total budget for LLM context in 2023 was about 4096 tokens, or roughly 3000 words. LLM context has to include all input, instructions and output, so this is actually incredibly restricted when you’re wanting to summarise the content of thousands of papers. My approach to this was to apply a technique that’s been around for a while - topic modelling.
In topic modelling we take our sentences, and do something to them to turn them into vectors, then we cluster those vectors and extract ‘topics’ from the clusters. I chose to use a very small model to do my topic modelling, the sentencetransformers sentence-transformers/all-MiniLM-L6-v2 model, a transformer that ingests up to 256 tokens and spits out a vector of 384 dimensions representing the semantic meaning of the sentence. This is a choice, motivated by a desire to process as much as posible, as fast as possible, and without needing to use a GPU. In hindsight, it probably would have been better to use a model with more biological pretraining, so that the biological meanings were better clustered (something like PubMedBERT), but this very small simple model did an ok job.
To cluster the vectors, we actually have to reduce that 384 dimensional vector down to a more manageable dimension. This is down to the curse of dimensionality. In a high dimensional space, the volume of the space grows exponentially, meaning the data becomes very sparsely distributed. The upshot of that is that the distance between points becomes useless - the distance to the nearest point is almost the same as the distance to the farthest.
The knee-jerk approach to dimensionality reduction is Prinicpal Component Analysis (PCA) which extracts the N eigenvectors of the data’s covariance matrix along which most of the variation occurs, and maps everything onto those. This lets you capture as much of the variability as possible without needing all the dimensions.
The more modern approach is the Uniform Manifold Approximation and Projection (UMAP). In this, the algorithm first evaluates the topology of the data in the high dimensional space by finding the K nearest neighbour graph for the data. then, using the assumption that the data lies in a high-dimensional manifold, it initialises a low-dimensionality represntation and optimises it until the KNN graph in low dimensions matches that in high dimensions (or is close). By doing this, UMAP preserves the global structure of the data, and its density.
In LitSumm, I chose to reduce the dimensionality of the vectors down from 384 to 20. UMAP runs on the whole collection of data from all sentences about a given ncRNA, so it should be preserving the structure of the semantic meaning of sentences from a bunch of different papers, all of which mention the RNA.
After dimensionality reduction, we have to cluster the data. To do this, LitSumm applies the HDBSCAN algorithm. This is a density aware, heirarchical clustering algorithm that tries to keep dense islands of connected points together, while repelling isolated points of ‘noise’. This is exactly what was neede for LitSumm where we wanted clusters of sentences about broadly the same topic, and to identify and ignore sentences that made singular, uncorroborated statements about the RNA. The other nice thing about HDBSCAN is that if gives you a cluster exemplar - kind of like the centroid of the cluster.
So, at this point LitSumm has several thousand sentences, embedded with a language model, dimensionality reduced and clustered. Great. The important bit comes next, where the LLM context is filled in one of four ways:
- Take everything. If the total token count of all the non-noise sentences is less than 2600, take them all. Organise the context such that the topics appear together as pseudi-paragraphs.
- Round-robin sample. If there aren’t too many (<20) clusters, round robin sample from each, starting with its exemplar, until we hit the context limit. Again, organise the context such that topics appear together in pseudoparagraphs.
- Exemplar sampling. If we have a lot of clusters, take the exemplar from each and use that. Sample more from bigger clusters if there is space.
- Maximum diversity sampling. Choose a cluster at random, take its exemplar. Find the cluster exemplar farthest away from the sampled one, sample that. Then find the exemplar farthest from both, take that, and so on.
These sampling techniques are increasingly complex, and increasingly sparingly used. The maximum diversity sampling approach only got used on a few RNAs that have tens of thousands of papers (XIST, HOTAIR and co). The vast majority worked with round-robin sampling.
Initial Summarization
The aim of the game is to make a literature summary with the following properties:
- No hallucinated facts
- Citations for statements that relate to real papers
- Factual accuracy - the summary must be factually similar to the context it came from.
To that end, the first summary is created with this prompt:
As an experienced academic who ALWAYS provides references for each sentence you write, produce a summary from the text below, focusing on {ent_id} and using the references for each sentence.
{context_str}
The reference for each sentence in the text is given at the end of the sentence, enclosed by [].
For example, the first sentence has the reference [{first_ref}].
References should only be provided at the end of sentences, and MUST follow the style in the context. Do not list references at the end of the summary.
You MUST provide at least one reference per sentence you produce.
Use only the information in the context given above. Start your summary with a brief description of {ent_id}, noting its type.
Use 200 words or less.
Summary:As you can see, this is quite prescriptive about how to write the summary, and makes a lot of the importance of having references in the summary. This is based on the best knowledge at the time about how to get the LLM to do what you want: repeating instructions multiple times, loading the large context ahead of the instructions, and giving examples. As far as I know, this is still the way it is done.
Reference Checking & The “Rescue” Loop
Once the model spits out its first-pass summary, we don’t just take its word for it. LitSumm evaluates the references in the generated summary using five automated checks:
- Adequacy of references: We require at least 0.5 references per sentence. You can’t write a long, detailed paragraph and only cite one paper at the very end.
- Formatting of references: The model must use PubMed Central identifiers formatted exactly like
PMCXXXXXX. No raw URLs or bracketed numbers. - Realness of references: We check all cited PMCIDs against the input context. If the model invented a PMCID that wasn’t in the original text, it fails.
- Location of references: The citations should be at the end of the specific sentences they support, rather than stacked in a big block at the end of the paragraph.
- Citations per instance: This prevents the model from packing too many PMCIDs into a single citation (e.g., citing ten papers for a single basic claim). We require that no single citation contains more than 50% of the total references.
If any of these checks fail, we trigger a “rescue” prompt tailored to that specific failure mode. The model is given the failed summary, told exactly what it got wrong with the references, and asked to fix it. We capped this at a maximum of four attempts to keep API costs in check and prevent infinite loops. If it still couldn’t get it right after four tries, we flagged the summary as problematic and moved on.
Veracity and Self-Consistency
If the references look good, we move on to fact-checking. We wanted to be absolutely sure the LLM wasn’t making things up, so we designed a self-consistency check that leverages the LLM itself as a judge.
First, we ask the model to break its own summary down into a bulleted list of individual assertions. Then, we feed those assertions back to the model alongside the original context. The model has to evaluate each assertion and state whether it is TRUE or FALSE based only on the context, providing a detailed explanation of its reasoning.
If any assertion is flagged as FALSE, we feed that explanation back into the model as a revision prompt:
{checked_assertions}
In light of the above checks about its veracity, refine the summary below to ensure all statements are true.
Original summary:
{summary}
Do not change the reference style used, but you may add or remove references.
Revised summary:This combination of chain-of-thought self-checking and iterative refinement proved to be incredibly powerful at filtering out hallucinations before the summaries ever hit the database.
Results and Expert Curation
In the end, we ran this pipeline on 4,618 RNA identifiers, which mapped to roughly 28,700 transcripts and 4,605 unique sequences in RNAcentral, drawing from a pool of about 177,500 papers. The distribution of RNA types was mostly dominated by lncRNAs (40.86%) and miRNAs (33.10%), with some pre-miRNAs (15.43%) and snoRNAs (6.50%) mixed in.
On average, generating a finished summary took 29 seconds and cost about $0.05 per RNA using the gpt-4-1106-preview API.
To see if they were actually any good, four of us (including a professional curator) did a blind evaluation of 50 randomly selected summaries. We rated them on a 1-to-5 scale (where 3 is acceptable and 5 is excellent).
The results were encouraging: * 94% of the summaries were rated 3 or above (good or excellent). * The automated reference checks caught issues in 2.1% of the summaries, and the rescue loop successfully resolved 76% of those, giving a final reference pass rate of 99.5%. * The self-consistency check flagged issues in 17.3% of the summaries, and the revision step successfully corrected 51% of them, resulting in a final consistency pass rate of 91.5%.
If a summary ultimately failed either check, we kept it in the database but hid it from public view on RNAcentral. In total, out of 4,605 unique sequences, we were able to display high-quality summaries for 4,602 of them.
What I’d Do Differently Now (and Limitations)
While I’m proud of how LitSumm turned out, looking back there are several limitations and design choices I’d reconsider today:
- I Hate Topic Modeling: At the time, using UMAP and HDBSCAN to cluster sentences and select exemplars felt like a clever way to squeeze text into a 4,096-token context window. In practice, though, topic modeling can pull semantically similar sentences together even if they describe completely different biological contexts. When the LLM tries to synthesize these, it can easily create false connections. Today, a clean Retrieval-Augended Generation (RAG) pipeline with semantic search over chunks would be much less error-prone.
- Reference misattribution: We sanity checked that the claims come from a real reference, but not that the cited reference matches the claim. While our checks caught blatant hallucinations, subtle misattributions still slipped through.
- LLMs are too excitable: The model loves to elevate a minor correlation in a paper to a definitive statement. Everything “is a promising biomarker for cancer.”
- Unsupported expansions: Every now and then, the model would hallucinate acronym expansions. For instance, it expanded “DFU” to “Diabetic Foot Ulcer” even though the word “diabetes” was nowhere in the source text (nor was foot, or ulcer)!
- Lots of knowledge is paywalled: Because we relied on the EuropePMC API and needed the full text, we restricted ourselves to the open-access subset. This means we missed out on decades of older literature and paywalled papers that human curators would normally have access to.
Despite these limitations, LitSumm represents a huge step forward for ncRNA curation. It was a relatively simple way to get a fairly high-quality summary form the literature about RNAs that previously had no such summary, and in doing so, hopefully gave researchers an easy way to get a quick overview of their RNA of interest.