GOFlowLLM
Gene Ontology Curation with LLMs
How can a fixed pool of curators ever hope to keep up with an exponentially expanding set of literature?
Since 2000, over 230,000 papers have been published on ncRNA, with more than half of those coming out in the last few years alone. The work of extracting facts from these papers and structuring them into knowledgebases like the Gene Ontology (GO) falls on a tiny pool of 100–200 biocurators worldwide. Of those, only a handful work on ncRNA with most of their time being dedicated to protein curation.
Because of this bottleneck, only about 1,400 articles about microRNAs (miRNAs) have been manually curated into the GO database over the course of about 20 years.
This was the motivation behind GOFlowLLM—an automated curation assistant designed to translate expert curation flowcharts into structured LLM reasoning paths.
You can check out the source code on GitHub at RNAcentral/GO_Flow_LLM.
- What is it? GOFlowLLM is a tool that automates Gene Ontology (GO) curation for microRNAs by having an LLM walk through expert-designed curation flowcharts.
- The Secret Sauce: We use constrained decoding (via
guidanceandllama.cpp) to force a local QwQ-32B model to answer predictably. This requires running a local model rather than using commercial APIs. - Scale: It processed 6,996 papers in 58 hours, generating 2,538 new candidate annotations, doubling the volume of total miRNA curation to date.
- Human in the loop: Coupled with Argilla, it cuts curation time per paper from 30 minutes to 5–10 minutes.
The Idea: LLMs + Flowcharts
Most attempts to automate GO curation rely on text mining or zero-shot extraction. While those show promise, they struggle with the nuance of scientific papers—conflating different assays, missing negative results, or failing to capture exact regulatory relationships.
My approach with GOFlowLLM was different: instead of asking a model to read a paper and “write the GO annotations,” we have the model follow the exact decision tree that a human curator uses.
The GO consortium has an expert-designed flowchart (see figure 1 below) to guide curators through curating miRNA-mediated gene silencing. It asks simple, binary questions at each node: - Is there experimental evidence? - Is there a functional interaction validated by a reporter assay (like a luciferase assay)? - What is the effect on endogenous target gene expression?
By breaking down the curation process into node-by-node yes/no questions, we turn a complex cognitive task into a series of structured reasoning steps. This flowchart can turn an enthusiastic undergraduate into a competent curator, maybe it will work as an agent harness for an LLM?
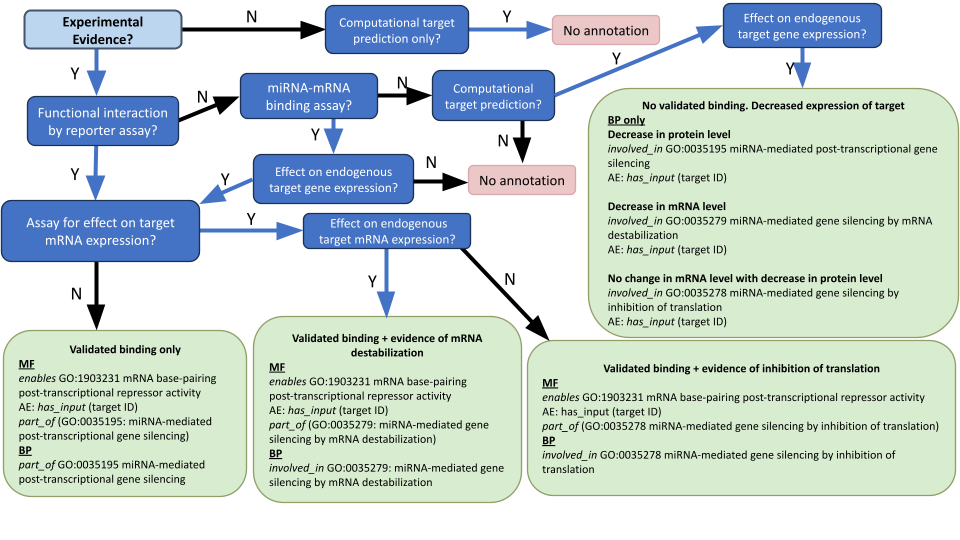
GO:0035195 (general silencing), GO:0035278 (inhibition of translation), and GO:0035279 (mRNA destabilization).
Constrained Decoding
LLMs talk too much. Ask them to say “yes” or “no,” and they’ll write a paragraph explaining their reasoning first. Worse, if you then want to extract something from that LLM output (gene names, for example), you may have a nightmare parsing job on your hands
To partially solve this, GOFlowLLM uses constrained decoding.
Instead of letting the model output whatever it wants, we use the guidance library and llama.cpp to modify the model’s log-probabilities during token sampling. For example, when the model reaches a decision node, we restrict the allowable token space to only the words "yes" and "no". The model is mathematically forced to make a clean, unambiguous choice that does not require any postprocessing.
This architectural choice has a major trade-off: it precludes the use of API-based models (like OpenAI’s GPT-4 or Anthropic’s Claude) because you cannot alter the sampling distribution behind their APIs. Instead, we run a local, 8-bit quantized version of the QwQ-32B reasoning model on NVIDIA A100 GPUs. QwQ is an excellent fit here because it is a reasoning model—it generates up to 1024 reasoning tokens (a “thinking trace”) before it commits to the constrained "yes" or "no" answer.
Guidance allows us to do a lot more than just force a binary choice though. I have it set up to select from lists of things (EuropePMC says these 10 genes are mentioned in the paper, which is the target?) and even extract guaranteed-to-be-real substrings from the paper as supporting evidence for the LLM’s claims.
** This may not be the case so much now**. Models like the Gemini series have ‘JSON mode’ which can be used to force them to follow a JSON schema that does almost the same thing. However some of the fancier stuff GoFlow does, like evidence substring extraction, still isn’t (AFAIK) doable with these models.
Section-by-Section Loading & Target Extraction
Feeding an entire paper into a local LLM is often unnecessary, and wastes context. To speed things up, GOFlowLLM works on article sections dynamically:
- Zero-Shot Section Classification: We ask the LLM to map the paper’s actual section headings (which vary wildly from paper to paper) to standard labels like “Methods” or “Results.”
- On-Demand Loading: We only load and feed the text of the section relevant to the current flowchart node.
- Target Gene Extraction: A major source of errors in text mining is extracting the wrong target gene. We solve this by querying the EuropePMC annotations API to get a pre-validated list of gene/protein symbols mentioned in the paper. We then use constrained generation to force the LLM to select its target from this exact list.
Results: Doubling the Curation Volume in 58 Hours
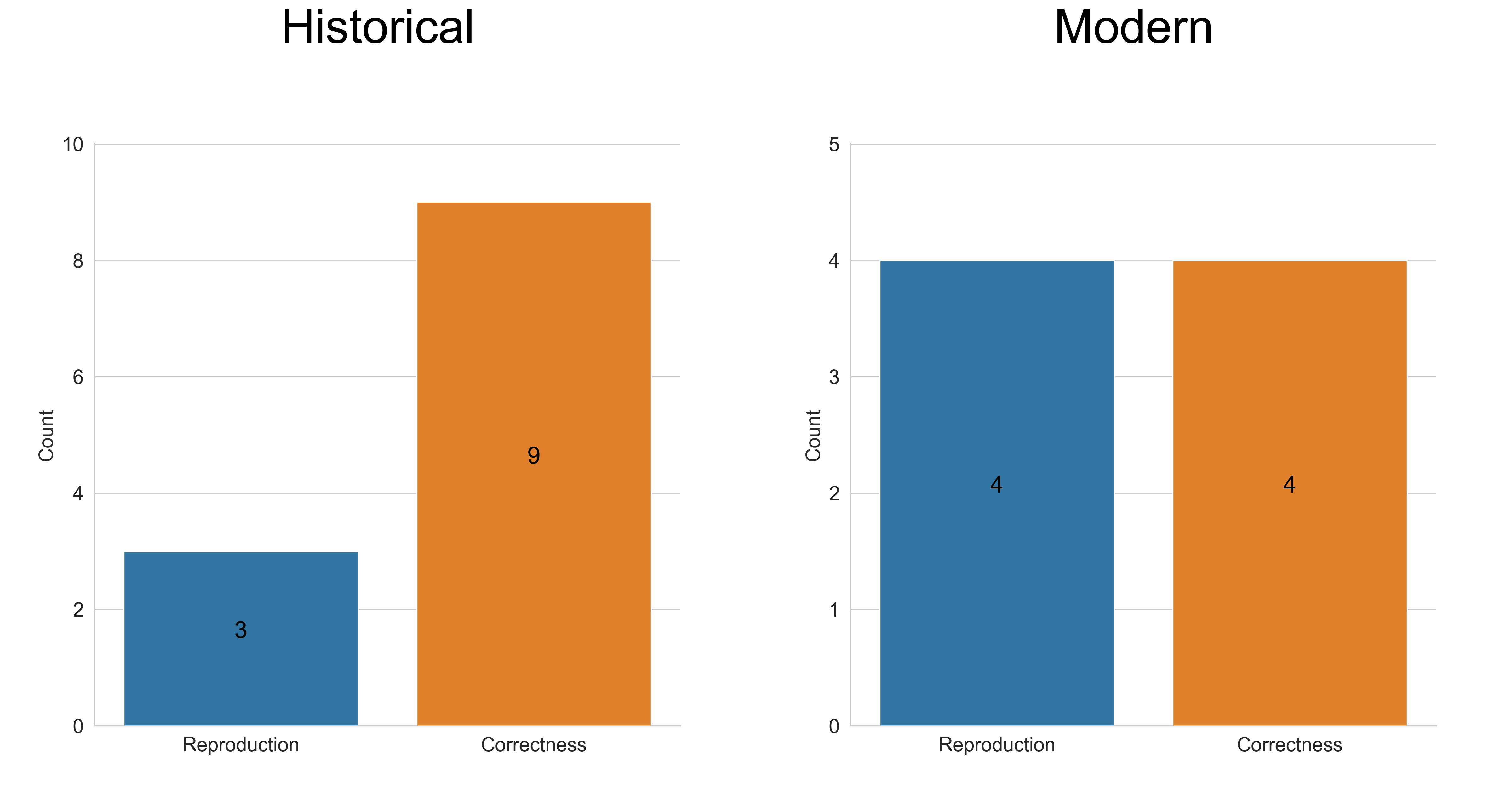
The first validation was on papers that had already been manually curated: * Recent Curation (Post-2022): GOFlowLLM reproduced the human curator’s exact GO terms in 81% of cases. * Historical Curation (Pre-2022): Reproduction accuracy was only 30%.
But this wasn’t a failure. In late 2021, the GO consortium introduced a new, more specific term (GO:0035279 for mRNA destabilization). Human curators hadn’t gone back to update old annotations, but GOFlowLLM automatically applied the new guidelines—achieving 90% correctness on manual review and effectively upgrading historical curation.
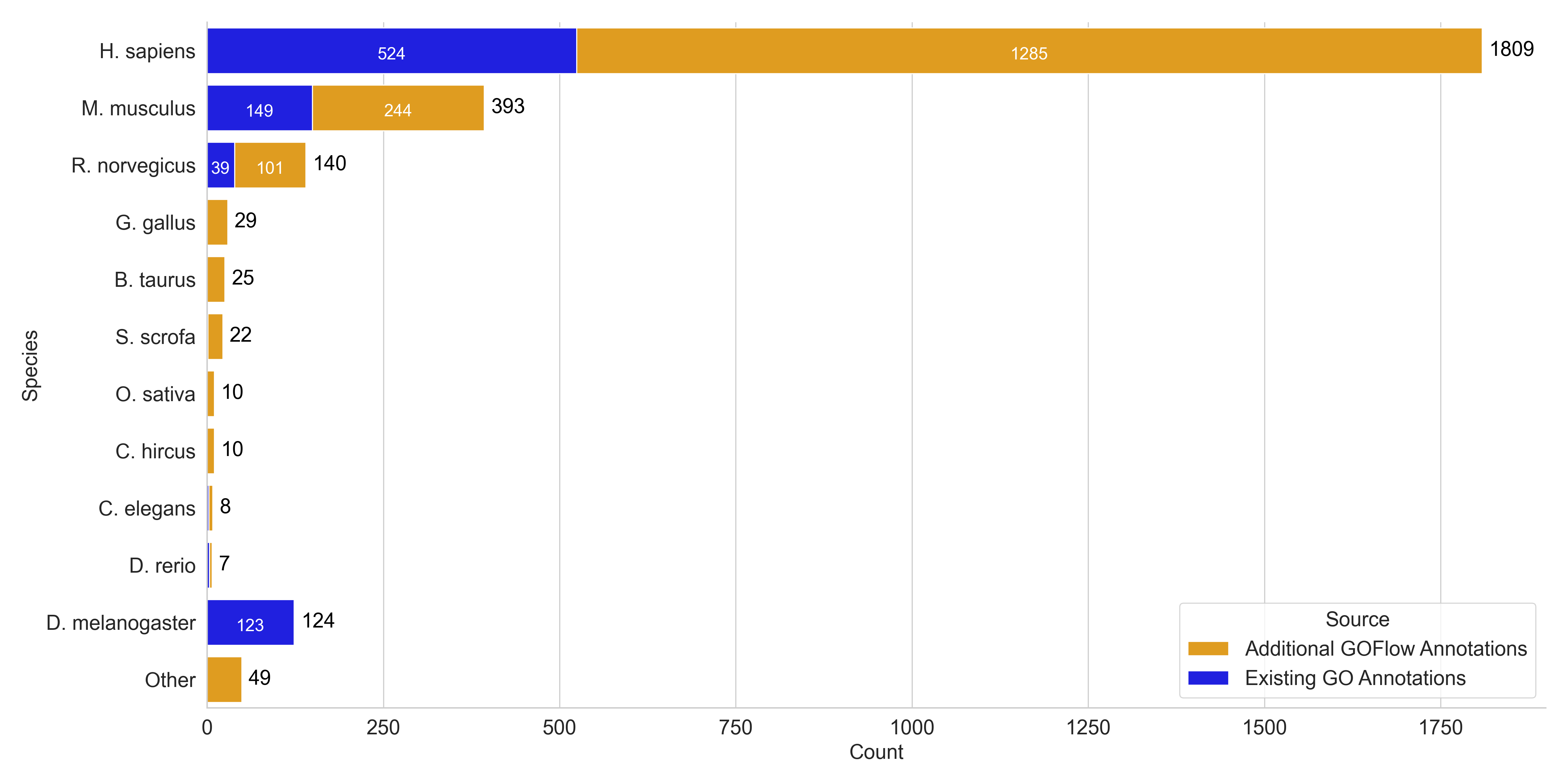
After validation, we set GOFlowLLM loose on a novel dataset of 6,996 previously uncurated papers identified by RNAcentral’s LitScan tool.
Using 4× A100 GPUs, the system chewed through the entire set in 58 hours (averaging 109 seconds per paper). It identified 2,538 new candidate GO annotations across 1,785 articles—essentially doubling the total volume of miRNA GO curation ever produced!
When expert curators manually reviewed a sample of these new annotations via Argilla, they agreed with: - The selected GO term in 87% of cases. - The model’s reasoning trace in 92% of cases. - The supporting text evidence in 93% of cases.
By providing these transparent reasoning traces in the Argilla UI, GOFlowLLM cuts curation time per paper from 30 minutes down to just 5–10 minutes. And by recording the decisions at each node, the reasoning behind them and the supporting evidence, GoFlowLLM provides a more granular curation artefact than ever before.
Where It Fails (and What’s Next)
GOFlowLLM has a few clear limitations:
- qRT-PCR Misattribution: The most common failure mode (responsible for most incorrect annotations) was the model misattributing qRT-PCR results. It would frequently get confused by papers reporting a decrease in mRNA levels without verifying if it was due to translation inhibition or mRNA destabilization, leading to overly specific annotations.
- Target Extraction: In about 25% of cases, the target extraction failed to recover the clean list because it selected too many genes from the EuropePMC list—specifically, genes mentioned in the paper but not validated as miRNA targets.
- Supplementary Data: Papers often report key validation assays (like qRT-PCR) in their supplementary materials. Since GOFlowLLM can (so far) only read the main open-access paper text, it misses these and reports no curatable data.
Future Work
GoFlow should be able to curate anything where there is a flowchart available. I’m going to try it on lncRNA (whose flowchart can be found on the GO wiki), and I want to try running on papers that report on lots of RNAs. GoFlow will be folded in as part of the RNAcentral release process, and will soon be providing data to GO central, and from there the world!
It would also be really cool to expand the flowchart idea to other terms. Curators usually agree on what annotations can be made from a paper, so I reckon they have a latent flowchart in their heads. I’m trying to see if I can reverse engineer that from a given term and paper collection!